
怎么提Issue与PR
https://www.cnblogs.com/daniel-hutao/p/open-a-pr-in-github.html
https://blog.csdn.net/qq_47733361/article/details/133907433
虽然经常使用github拉开源项目学习,也开源过一些自己写的程序,但是还未实际参与过开源社区😂。
我在了解学习 隐语 的过程中,看到一处文档笔误。然后前两天在隐语群里,也正好看到过一个招募贡献者的帖子。突然就想着是不是自己可以参加一下,因为我对参与开源项目、社区很感兴趣,由此开始第一次提PR。
1.提Issue1.1 相关知识概念什么是提issue,Issue(字面意思 “议题”)是项目的「问题跟踪工具」。我认为它是一个反馈问题/提需求 的工具。主要用于记录和解决项目的“待办事项”。
核心用途(什么时候提issue):
反馈 Bug:比如你用某个开源工具时,发现 “点击按钮没反应”“数据计算错误”,就可以提 Issue 告诉维护者 “哪里出了问题、怎么复现”。
提出需求:比如你希望项目增加新功能(“能否 ...
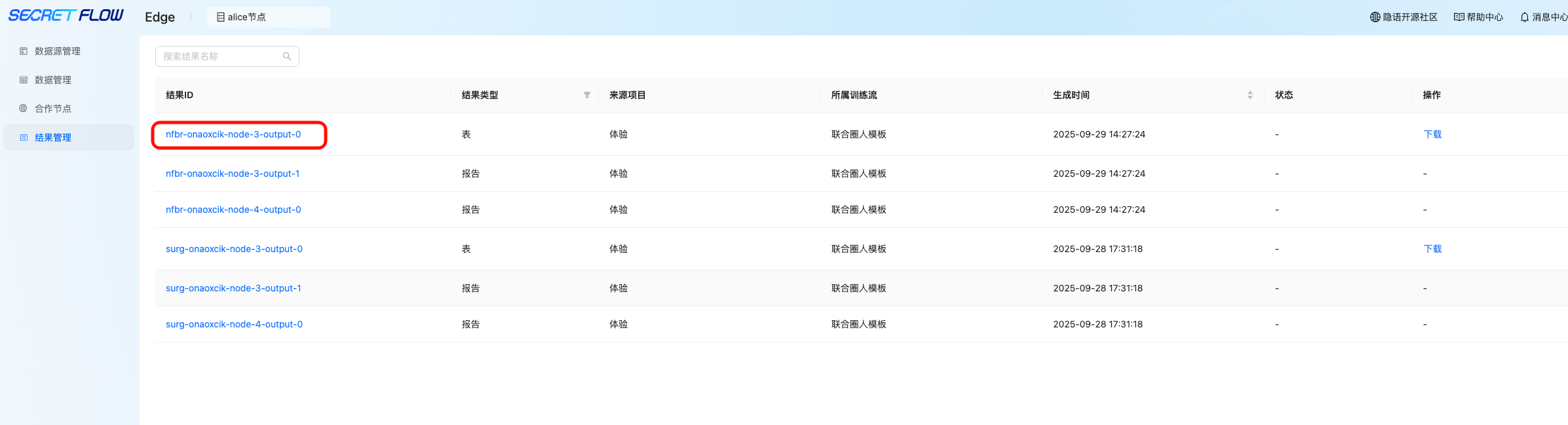
SecretPad All in One 中心化部署模式——安装部署测试
官方文档:https://www.secretflow.org.cn/zh-CN/docs/secretpad-all-in-one/v1.11.0b1/center_deploy/platform_installation_guidelines_center
项目README文档:https://github.com/secretflow/secretpad/blob/main/README.zh-CN.md
这一块我还是折腾了一下,所以记录下。
注:v1.11.0b1版本还不是可以拆箱即用,没有bug和问题的。我在安装和使用过程,其实也发现了一些小问题(系统本身的)。如果你看本文的目的是直接部署商用,并且期待很高,那么可能些许失望。
我对于这个项目的认识在于:它起到一个很好的引领、引导作用,让我们学习使用隐私计算。
1.前置条件按官方文档即可,主要就是安装好docker,没什么门槛。我的设备是 Mac M4 + docker 28.2.2。
2.下载部署文档编写时最新的部署包在这:https://www.s ...
单机搭建 kuscia多机部署点对点集群
官方文档:https://www.secretflow.org.cn/zh-CN/docs/kuscia/v1.0.0b0/deployment/Docker_deployment_kuscia/deploy_p2p_cn
官方文档写的是很详细的,不过它是基于多机进行部署的,然后搭建bob节点那没有详细写。这里我记录下,我用mac 单机来搭建kuscia 点对点集群。
注:文中步骤流程以及一些内容都是参照官方文档的。
1.前置准备
在部署 Kuscia 之前,请确保环境准备齐全,包括所有必要的软件、资源、操作系统版本和网络环境等满足要求,以确保部署过程顺畅进行,详情参考部署要求。
要求还是很低的,Docker 20.10.24及以上,有2G内存。节点默认使用 SQLite 作为存储,所以也不需要准备mysql。所以有了docker就可以直接开整啦。
2.部署流程(基于 TOKEN 认证)新建一个kuscia文件夹,然后其中再新建两个文件夹alice和bob。后面就把这两个文件夹当作两个机器。
2.1 部署 alice 节点到alice文件夹 ...
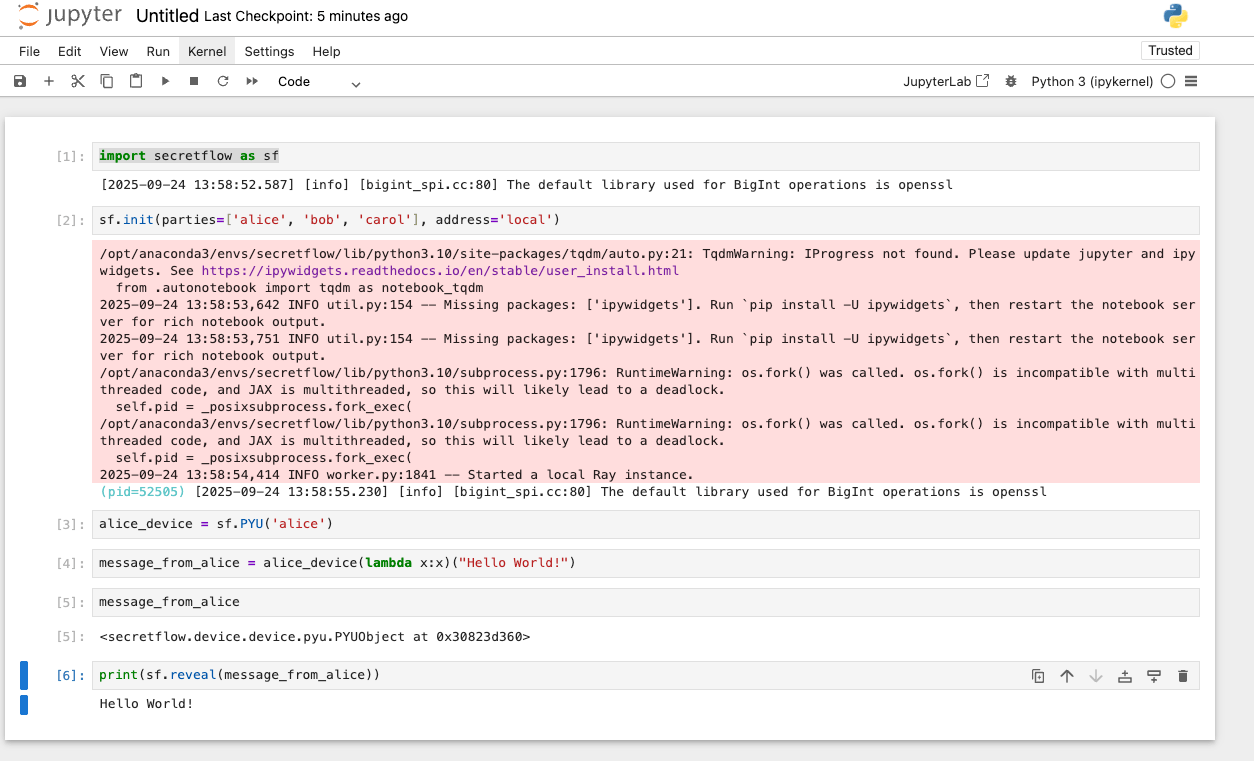
隐语Secretflow—源码编译安装体验
官方快速开始文档:https://www.secretflow.org.cn/zh-CN/docs/secretflow/v1.12.0b0/getting_started/installation#option-3-from-source
官方提供四种方式安装SecretFlow。我使用的设备是:Mac M4|macOS Sequoia15.6.1,已安装anaconda。
我最早是希望尝试使用源码方式安装的,然后出现了些问题,虽然解决了但是需要安装一些其他软件工具,所以还是比较麻烦的。
我也试了 pypi 方式,这种方式最简单。如果不改源码的情况,用这种方式完全可以。下面我两种方式都写了。
1.从pypi安装这块直接参照官方的安装说明即可,非常简单。
https://www.secretflow.org.cn/zh-CN/docs/secretflow/v1.12.0b0/getting_started/installation#option-3-from-source
请注意python版本需要是3.10,你可以用conda构建一个 ...

DNS投毒原理与过程要理解 DNS 缓存污染(DNS Cache Poisoning,也叫 DNS 投毒)的实现原理,核心要抓住两个关键点:DNS 协议的 “信任漏洞” 和 缓存服务器的 “存储逻辑” —— 攻击者正是利用了这两个特性,把 “假应答” 伪装成 “真应答”,让缓存服务器 “信以为真” 并保存,进而污染所有依赖该服务器的用户。
1.先了解DNS 缓存服务器的 “正常工作逻辑”得先知道缓存服务器 “正常情况下怎么接收和存储应答”,这是理解污染的基础:
当用户向缓存服务器(比如运营商的 114.114.114.114)查询某个域名(如baidu.com)时:
若缓存服务器本地没有baidu.com的解析记录(缓存未命中),它会先向 “上级 DNS 服务器”(如.com顶级域服务器)发送DNS 查询请求(比如问:”baidu.com的 IP 是多少?”);
上级服务器收到请求后,会返回一个DNS 应答包,里面包含baidu.com→180.101.49.12的真实映射;
缓存服务器验证这个应答包 “确实是对自己刚才查询的回复” 后,会把这个映射存入本地缓存(通常保留几小时到几天 ...

计算机网络核心概念串烧在学习软考的时候,发现对于计算机网络有些概念都有点遗忘了。所以这里特意将一些核心概念通过一个示例串联起来,方便理解和记忆。
我以“设备访问某个域名(如www.baidu.com)” 的全过程为例子,沿着 “终端身份配置→DNS 解析(域名转 IP)→局域网内转发→跨网到公网→公网路由传输→目标服务器响应” 的完整链路拆解,同时串联 DHCP、DNS、IP、MAC、ARP、路由器转发等核心概念。
1.主要示例下面以 “家用电脑通过 Wi-Fi 访问www.baidu.com” 为例
前置:电脑通过 DHCP 获取局域网身份(上网基础)电脑刚连接家庭 Wi-Fi 时,无 IP 地址,需通过DHCP(动态主机配置协议) 从路由器获取 “局域网通信资格”:
电脑向局域网广播 “DHCP 发现报文”(目标 MAC:FF:FF:FF:FF:FF:FF,目标 IP:255.255.255.255),询问 “谁能分配 IP?”;
家庭路由器(默认开启 DHCP 服务)收到请求后,单播回复 “DHCP 提供报文”,包含核心配置:
局域网 IP:192.168.1.100(电脑的 ...
Linux 常见系统日志分类及说明/var/log 是 Linux 系统的核心日志目录,存储了系统、服务、应用的运行状态、错误信息及安全事件等关键日志。不同发行版(如 Ubuntu/Debian、CentOS/RHEL)文件略有差异,但核心文件及功能基本一致,以下是最常见的日志文件分类及说明:
一、系统核心日志记录系统整体运行状态、启动 / 关机、内核事件等,是排查系统故障的首要参考。
日志文件
核心功能
/var/log/syslog
Debian/Ubuntu 核心日志:整合系统、内核、服务(如 SSH、 cron)的所有日志,信息最全面。
/var/log/messages
CentOS/RHEL 核心日志:功能同 syslog,记录系统非调试类的通用事件(如硬件检测、服务启停)。
/var/log/kern.log
仅记录 Linux 内核日志:如内核模块加载、硬件驱动错误、内存 / 磁盘异常(如磁盘 IO 错误、CPU 告警)。
/var/log/boot.log
系统 启动过程日志:记录开机 ...
debain服务器 守护进程日志归档文件清理1. 日志是谁写的?/var/log/daemon.log.1 是 系统守护进程(Daemon) 的日志归档文件,由系统的日志服务(如 rsyslog 或 syslog-ng)生成和管理。
核心来源:系统中后台运行的服务(如网络服务、硬件管理服务、进程管理服务等,非用户直接启动的程序)的运行日志。
.1 后缀:表示这是 归档日志(由日志服务按规则 “轮转” 生成的旧日志),原始实时日志是 /var/log/daemon.log。
2. 如何自动清理?无需 “禁止日志生成”(日志对排查问题至关重要),正确做法是通过 日志轮转工具(logrotate) 自动压缩、删除旧日志,配置步骤如下:
步骤 1:找到 logrotate 配置文件daemon.log 的轮转规则通常在以下文件中(二选一即可):
系统默认配置:/etc/logrotate.d/rsyslog(若用 rsyslog 服务)
自定义配置:可在 /etc/logrotate.d/ 下新建文件(如 daemon-log)
步骤 2:修改 / 添加轮转规则编辑配置文件( ...

Zeppelin 源码编译构建与打包部署
官方网站:https://zeppelin.apache.org/
github仓库:https://github.com/apache/zeppelin
官方构建说明文档:https://zeppelin.apache.org/docs/0.12.0/setup/basics/how_to_build.html
一、背景:本文是为了记录学习 Zeppelin 的编译构建以及debug的过程的。过程中遇到了不少问题,虽然最终都解决了,但是我建议在真正开始构建与了解源码之前,一定先读读 Zeppelin的提供的这两个文档,而不仅是构建文档。
https://zeppelin.apache.org/docs/0.12.0/usage/interpreter/interpreter_binding_mode.html
https://zeppelin.apache.org/docs/0.12.0/interpreter/spark.html#zeppelincontext
里面有介绍了 interpreter运行机制、Zeppelin Conf ...

一站式搭建Spark-Hadoop集群及Zeppelin在使用 zeppelin 的时候,可能想要使用真实的 spark、hadoop集群。但是无论是上是spark集群、还是hadoop集群都是比较麻烦。
zeppelin 0.12.0 要求spark版本高于3.2,我以前一篇文章里模仿教程的做的spark-hadoop镜像,其中spark版本比较低,zeppelin使用不了。所以我又制作了一个镜像,内置了spark3.5.6、hadoop3.4.0,可以很方便部署spark、hadoop集群。
如果想要zeppelin容器能配合使用这个spark、hadoop集群,还需要做一些网络上的联通、配置共享等处理的。
(1) docker-compose-with-zeppelin.yml 文件内容:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778 ...


