spark-submit 提交spark作业到k8s

spark-submit 提交spark作业到k8s
XRspark-submit 提交spark作业到k8s
本文主要介绍下 Spark On K8s 的运行流程。我在做一个产品的过程中有涉及到这一部分,虽然产品的实际情况比这复杂,但是了解了这个即可。
整体流程概述
当你使用 spark-submit 提交任务到 Kubernetes 集群时,整个过程可以分为两个主要阶段:
- 提交阶段:在你的本地机器或 CI/CD 环境中发生,
spark-submit与 Kubernetes API Server 交互。 - 执行阶段:在 Kubernetes 集群内部发生,由 Spark Driver Pod 和 Executor Pods 协同完成。
整个流程的时序图如下所示,清晰地展示了各个组件间的交互:
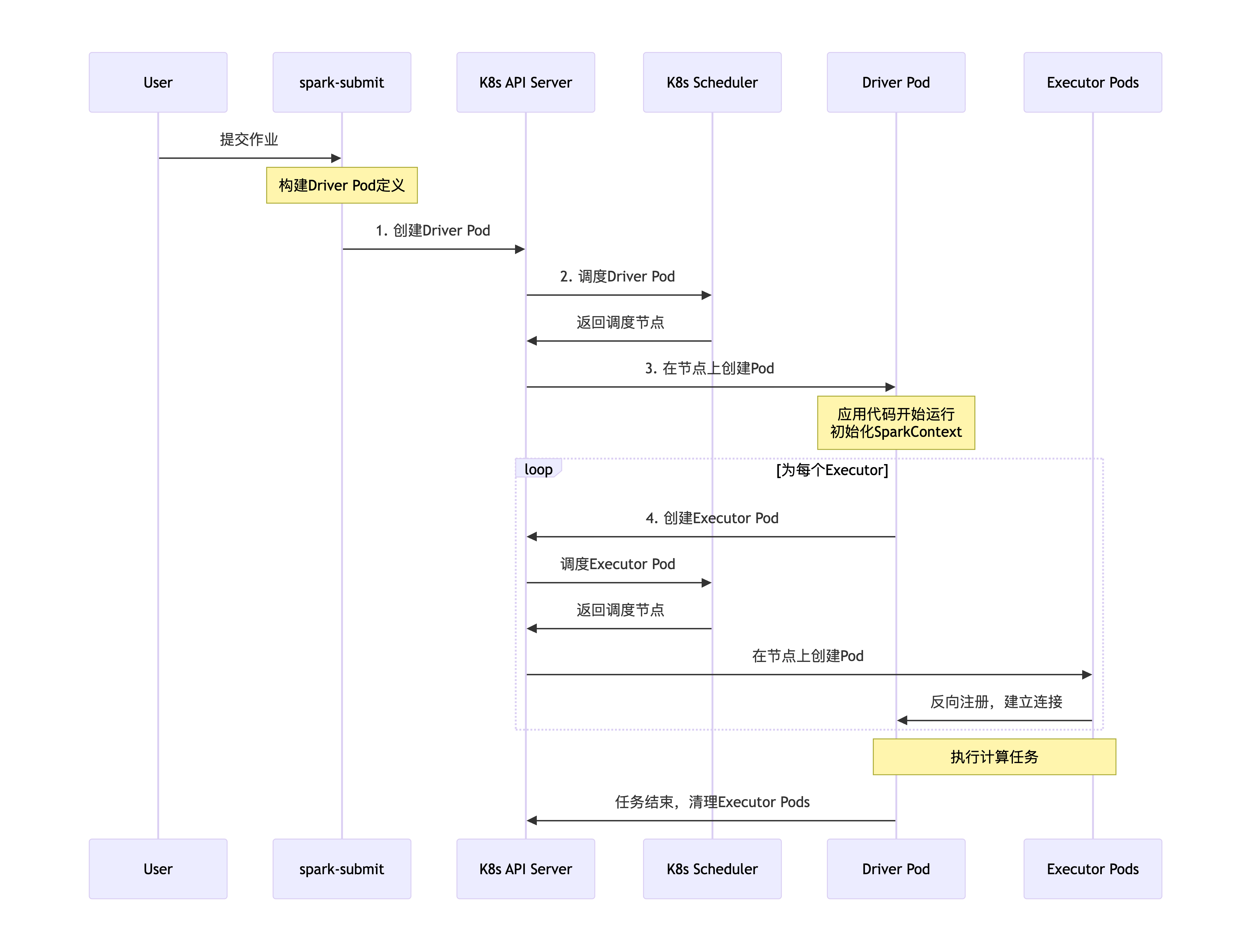
详细流程分解
阶段一:提交阶段 —— spark-submit 与 Kubernetes API Server 的交互
1.命令执行:你执行一个类似下面的命令:
1 | ${SPARK_HOME}/bin/spark-submit \ |
参数详细解析
下表详细解析了通过 spark-submit 将作业提交到 Kubernetes 集群时使用的各项参数。
1. 基础集群配置
| 参数 | 作用与说明 |
|---|---|
--master k8s://... |
作用:指定 Kubernetes API Server 的地址,作为 Spark Master。 说明:这是 Spark 与 K8s 集群通信的入口点。 |
--deploy-mode cluster |
作用:指定为集群部署模式。 说明:Driver 程序将会在 K8s 集群的一个 Pod 中运行,而不是在提交客户端上。 |
2. Kubernetes 核心认证与命名空间
| 参数 | 作用与说明 |
|---|---|
spark.kubernetes.namespace |
作用:指定 Spark 应用运行的 Kubernetes 命名空间。 说明:所有的 Driver 和 Executor Pod 都会在此命名空间中创建。 |
spark.kubernetes.authenticate.ssl.trustCerts |
作用:控制是否禁用 SSL 证书验证。 说明:在测试环境或使用自签名证书时可设为 false。生产环境建议启用并配置正确证书。 |
spark.kubernetes.authenticate.driver.serviceAccountName |
作用:指定 Driver Pod 使用的 Service Account。 说明:至关重要。此 Service Account 必须拥有创建和删除 Pod 的权限,否则 Executor 将无法启动。 |
3. Pod 命名与标识
| 参数 | 作用与说明 |
|---|---|
spark.kubernetes.driver.pod.name |
作用:自定义 Driver Pod 的名称。 说明:便于识别和管理,若不指定则会生成随机名称。 |
spark.kubernetes.executor.podNamePrefix |
作用:设置 Executor Pod 名称的前缀。 说明:所有 Executor Pod 名称都将以此前缀开头,方便在 K8s 中识别隶属于同一应用的 Pod。 |
4. 资源分配配置
| 参数 | 作用与说明 |
|---|---|
spark.driver.memory |
作用:设置 Driver 进程的堆内存大小(例如:1g)。 |
spark.executor.memory |
作用:设置每个 Executor 的堆内存大小(例如:2g)。 |
spark.executor.memoryOverhead |
作用:设置每个 Executor 的堆外内存。 说明:用于 JVM 开销、原生数据结构等。Pod 总内存 = executor.memory + executor.memoryOverhead。 |
spark.executor.cores |
作用:为每个 Executor 分配的 CPU 核心数(例如:2)。 |
spark.executor.instances |
作用:启动的 Executor 实例数量(例如:2)。 |
5. 网络与稳定性配置
| 参数 | 作用与说明 |
|---|---|
spark.shuffle.io.maxRetriesspark.shuffle.io.retryWait |
作用:配置 Shuffle 操作的失败重试次数和等待时间。 说明:在网络不稳定的环境中,增加重试有助于提高作业稳定性。 |
spark.driver.portspark.driver.blockManager.port |
作用:固定 Driver 的通信端口。 说明:在 K8s 环境中,固定端口可以简化网络策略(NetworkPolicy)的配置。 |
6. 容器镜像与拉取策略
| 参数 | 作用与说明 |
|---|---|
spark.kubernetes.container.image |
作用:指定包含 Spark 运行时和应用程序代码的 Docker 镜像。 说明:这个镜像是运行所有 Pod 的基础。 |
spark.kubernetes.container.image.pullPolicy |
作用:设置镜像拉取策略。 说明: IfNotPresent 表示如果本地已存在则不拉取,Always 表示总是重新拉取。 |
7. 高级 Pod 配置
| 参数 | 作用与说明 |
|---|---|
spark.kubernetes.driver.podTemplateFilespark.kubernetes.executor.podTemplateFile |
作用:通过模板文件对 Driver 和 Executor Pod 进行高级自定义。 说明:功能强大。可用于挂载数据卷(Volume)、设置环境变量、配置资源限制(limits/requests)、节点亲和性等。 |
8. 内存管理
| 参数 | 作用与说明 |
|---|---|
spark.memory.fraction |
作用:设置用于执行和存储的统一内存(Unified Memory)占总堆内存的比例(例如:0.7)。 |
spark.memory.storageFraction |
作用:在统一内存中,专门用于数据缓存(Storage)的内存所占比例(例如:0.2)。 |
9. 清理与生命周期
| 参数 | 作用与说明 |
|---|---|
spark.kubernetes.driver.service.deleteOnTermination |
作用:控制在 Driver Pod 终止时是否自动删除其对应的 K8s Service。 说明:设置为 true 可自动清理资源。 |
spark.worker.cleanup.intervalspark.worker.cleanup.appDataTtl |
作用:设置工作目录的清理间隔和应用数据的存活时间(TTL),单位为秒。 |
10. 应用代码与依赖
| 参数 | 作用与说明 |
|---|---|
--jars |
作用:通过逗号分隔的列表,指定需要分发到 Driver 和 Executor 的额外 JAR 包。 |
--py-files |
作用:对于 PySpark 应用,指定需要分发的 .zip, .egg, 或 .py 文件。 |
local:///path/to/app |
作用:指定应用程序代码在容器镜像中的路径。 说明: local: 前缀表示代码位于镜像内部,无需从外部下载。 |
<application-arguments> |
作用:传递给应用程序主类 main 方法的参数。 |
补充:其他重要参数
除了上述参数,以下配置在生产环境中也十分常用,特别是在资源管理和调度方面。
1. 动态资源分配 (Dynamic Resource Allocation)
| 参数 | 作用与说明 |
|---|---|
spark.dynamicAllocation.enabled |
作用:设置为 true 以启用动态资源分配。说明:Spark 会根据工作负载自动增减 Executor 数量,非常适合多租户和资源共享的环境。 |
spark.dynamicAllocation.minExecutors |
作用:动态分配下,Executor 的最小数量。 说明:确保即使在空闲时也保留指定数量的 Executor,以减少冷启动延迟。 |
spark.dynamicAllocation.maxExecutors |
作用:动态分配下,Executor 的最大数量。 说明:控制资源使用的上限,防止单个作业占用过多集群资源。 |
spark.dynamicAllocation.initialExecutors |
作用:作业启动时初始化的 Executor 数量。 |
2. 调度与亲和性 (Scheduling & Affinity)
| 参数 | 作用与说明 |
|---|---|
spark.kubernetes.driver.node.selector.[labelKey]spark.kubernetes.executor.node.selector.[labelKey] |
作用:通过节点标签(Node Selector)将 Driver 或 Executor Pod 调度到特定节点。 示例: --conf spark.kubernetes.executor.node.selector.disktype=ssd |
spark.kubernetes.driver.tolerations.[tolerationNum].[key/operator/value/effect]spark.kubernetes.executor.tolerations.[... |
作用:为 Pod 添加容忍度(Toleration),使其可以被调度到带有特定污点(Taint)的节点上。 说明:常用于将 Spark 作业调度到专用节点组。 |
3. 依赖与文件管理
| 参数 | 作用与说明 |
|---|---|
--files |
作用:指定需要上传到每个 Executor 工作目录的普通文件列表。 说明:例如配置文件、脚本等。 |
spark.kubernetes.file.upload.path |
作用:指定一个 Driver 可访问的 HDFS 兼容路径,用于上传作业依赖。 说明:当直接通过 k8s:// 提交时,此路径可作为依赖文件的中转站。 |
4. Pod 元数据
| 参数 | 作用与说明 |
|---|---|
spark.kubernetes.driver.label.[labelKey]spark.kubernetes.executor.label.[labelKey] |
作用:为 Driver 或 Executor Pod 添加自定义标签(Label)。 示例: --conf spark.kubernetes.driver.label.app-owner=team-a |
spark.kubernetes.driver.annotation.[annotationKey]spark.kubernetes.executor.annotation.[annotationKey] |
作用:为 Driver 或 Executor Pod 添加自定义注解(Annotation)。 说明:可用于集成监控、日志等第三方系统。 |



喜欢这篇文章的人也看了




评论
匿名评论隐私政策







