Zeppelin 源码编译构建与打包部署

Zeppelin 源码编译构建与打包部署
XRZeppelin 源码编译构建与打包部署
官方网站:https://zeppelin.apache.org/
github仓库:https://github.com/apache/zeppelin
官方构建说明文档:https://zeppelin.apache.org/docs/0.12.0/setup/basics/how_to_build.html
一、背景:
本文是为了记录学习 Zeppelin 的编译构建以及debug的过程的。过程中遇到了不少问题,虽然最终都解决了,但是我建议在真正开始构建与了解源码之前,一定先读读 Zeppelin的提供的这两个文档,而不仅是构建文档。
- https://zeppelin.apache.org/docs/0.12.0/usage/interpreter/interpreter_binding_mode.html
- https://zeppelin.apache.org/docs/0.12.0/interpreter/spark.html#zeppelincontext
里面有介绍了 interpreter运行机制、Zeppelin Configuration等等。
二、编译构建
2.1 步骤
1)准备要求:
| Name | Value |
|---|---|
| Git | (Any Version) |
| Maven | 3.6.3 or higher |
| OpenJDK or Oracle JDK | 1.8 (151+) (set JAVA_HOME) |
我使用的是 jdk11。jdk版本最好不要太高了,我一开始用的jdk21就编译出问题了。
2)下拉源码
1 | git clone https://github.com/apache/zeppelin.git |
3)编译源码
1 | ./mvnw clean package -DskipTests |
4)启动
1 | ./bin/zeppelin-daemon.sh start |
以上是什么都不出问题的步骤 😂,实际上可能会出现问题
2.2 遇到的问题
1)spark-3.5.3-bin-without-hadoop.tgz 损坏
报错:
1 | [INFO] ------------------------------------------------------------------------ |
原因:maven的下载插件下载下来的 spark-3.5.3-bin-without-hadoop.tgz 是损坏的。应该是maven下载中途停止了,导致其实下载下来的不完整(233MB),完整的应该是300MB左右。
Maven下载插件的缓存目录位于 /Users/kxr/.m2/repository/.cache/download-maven-plugin/
将原先maven缓存的损坏的spark-3.5.3-bin-without-hadoop.tgz给删除掉。
1 | rm -f /Users/kxr/.m2/repository/.cache/download-maven-plugin/spark-3.5.3-bin-without-hadoop.tgz_cab0a2ce6ec48d96124c50359f3fb6a1 |
然后我用浏览器单独下载了spark-3.5.3-bin-without-hadoop.tgz,然后将复制并重命名为 /Users/kxr/.m2/repository/.cache/download-maven-plugin/spark-3.5.3-bin-without-hadoop.tgz_cab0a2ce6ec48d96124c50359f3fb6a1
就这样来了一个偷梁换柱哈哈。然后就可以单独构建一下出问题的 rlang模块试下:
1 | ./mvnw clean install -pl rlang -DskipTests |
发现没问题了!
然后继续从rlang模块开始继续完成全部构建
1 | ./mvnw clean install -DskipTests -Dmaven.wagon.http.ssl.insecure=true -Dmaven.wagon.http.ssl.allowall=true -rf rlang |
2)jdk版本导致的编译报错
然后然后又出现新的报错了:
1 | INFO] ------------------------------------------------------------------------ |
进一步获取细节报错:
1 | ./mvnw clean install -pl flink/flink1.15-shims -e |
1 | [ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:4.9.2:compile (scala-compile-first) on project flink1.15-shims: scala compilation failed -> [Help 1] |
发现错误的根本原因是 Java 版本不兼容 。
1.错误信息 scala.reflect.internal.MissingRequirementError: object java.lang.Object in compiler mirror not found 表明 Scala 编译器无法找到 Java 对象,这通常是由于 Java 版本不兼容导致的。
2.通过查看项目的 POM 文件,我发现:
项目的根 POM 文件中指定了 Java 版本为 11 ( <java.version>11</java.version> )
Flink 模块使用的 Scala 版本为 2.12.7
使用的 scala-maven-plugin 版本为 4.9.2
额,是我忘记调 Java SDK了。
1 | export JAVA_HOME=$(/usr/libexec/java_home -v 11) |
1 | ./mvnw clean install -pl flink/flink1.15-shims -DskipTests |
发现编译没问题,继续:
1 | ./mvnw clean install -DskipTests -Dmaven.wagon.http.ssl.insecure=true -Dmaven.wagon.http.ssl.allowall=true -rf flink/flink1.15-shims |
3)flink/flink-scala-2.12 编译报错
1 | [INFO] ------------------------------------------------------------------------ |
这个报错,我当时也没注意具体排查,就是执行了下:
1 | # 安装 Flink 父级 POM |
好像就修复好了
1 | ./mvnw clean install -DskipTests -Dmaven.wagon.http.ssl.insecure=true -Dmaven.wagon.http.ssl.allowall=true -rf flink/flink-scala-2.12 |
1 | ./mvnw clean install -DskipTests |
4)类找不到
1 | WARN [2025-09-16 22:04:50,334] ({FIFO-RemoteInterpreter-spark-shared_process-shared_session-1} NotebookServer.java[onStatusChange]:1963) - Job paragraph_1758022969766_1777889232 is finished, status: ERROR, exception: null, result: %text org.apache.zeppelin.interpreter.InterpreterException: org.apache.zeppelin.interpreter.InterpreterException: Fail to open SparkInterpreter |
1 | ./mvnw clean package -pl spark/scala-2.12 -DskipTests |
1 | Users/kxr/learning/zeppelin/zeppelin-server/src/main/java/org/apache/zeppelin/rest/CredentialRestApi.java:36:32 |
依赖存在问题,我尝试的解决方法是:找到Credentials属于哪个模块,然后重新编译下那个模块。
1 | cd zeppelin-zengine |
确实解决问题。
以上就是我遇到过的编译问题。这里只是记录下,不一定会遇到——我后面几次编译都是一次正常完成。
三、IDEA运行与Debug
问题不仅仅在编译哦😂 咱们继续下面也有坑
3.1 IDEA运行
启动类:org.apache.zeppelin.server.ZeppelinServer
环境变量:ZEPPELIN_LOCAL_IP=127.0.0.1
VM参数:-Dzeppelin.server.rpc.port=12345(这个可以不填,这个是我排查问题测试用的)
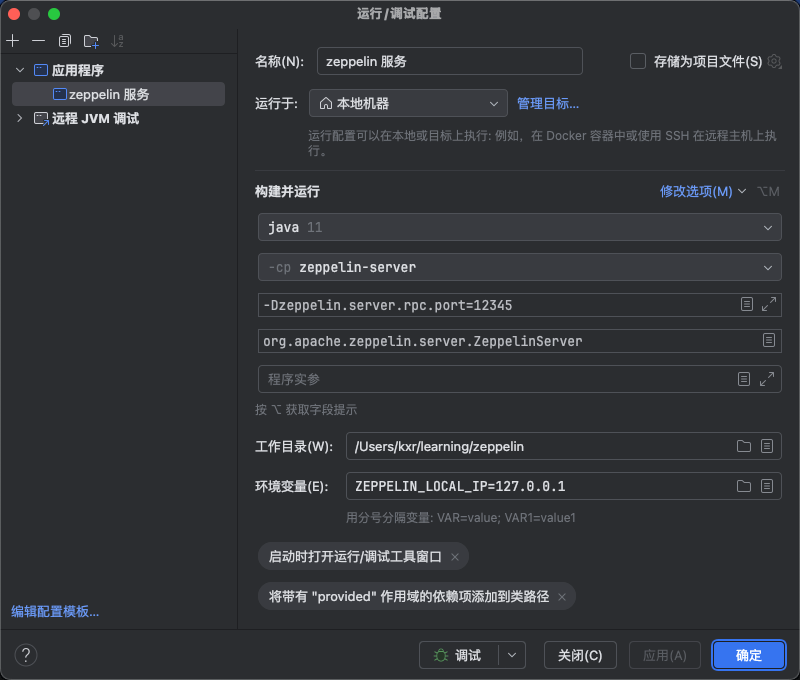
编辑好启动配置,就可以开始运行,系统启动起来之后访问:http://localhost:8080/
web页面上新建一个文件夹和笔记:
1 | %spark |
可以设置断点:
- org.apache.zeppelin.scheduler.RemoteScheduler#runJobInScheduler
- org.apache.zeppelin.notebook.Paragraph#jobRun
然后页面点击运行图标,你就可以debug到了。
备注:这里提醒一下 web页面需要配置下spark解释器的 SPARK_HOME,即需要提前下载一个spark(zeppelin0.12.0 适配spark3.3到spark3.5)。但是如果成功编译,其实zeppelin项目也会自己下载一个spark,存放的路径: spark/interpreter/target/spark-3.4.3-bin-without-hadoop。可以配置这个也行。
如果有自己之后想要对接的spark集群,可以单独下载对应的spark版本,比如我用的是spark3.5.6
3.2 网络问题
1)问题现象与解决
在上面我debug到断点之后,放行。但是页面一直卡在pending状态
1 | INFO [2025-09-17 10:14:13,663] ({FIFO-RemoteInterpreter-spark-shared_process-shared_session-1} ProcessLauncher.java[launch]:96) - Process is launched: [.//bin/interpreter.sh, -d, .//interpreter/spark, -c, 0.0.1.1, -p, 58194, -r, :, -i, spark-shared_process, -l, .//local-repo/spark, -g, spark] |
然后等待一段时间之后,本地logs目录下,可以发现这样的报错:
1 | WARN [2025-09-17 16:09:13,170] ({main} Logging.scala[logWarning]:72) - Your hostname, kxrdeMacBook-Pro.local resolves to a loopback address: 127.0.0.1; using 192.168.231.196 instead (on interface en0) |
这个问题原因是:网络配置问题,使用了 0.0.1.1 这个特殊的 IP 地址
表现:解释器进程启动但无法注册到 Zeppelin 服务器
修复:这个问题我问了claude4、claude3.7 。经过几次拷打,它们加了很多的配置,也修复了问题。然后我就想知道是哪个配置真正解决了问题。
ai加了 VM参数、环境变量、spark-env.sh、zeppelin-env.sh、zeppelin-site.xml配置文件等。但是实质上真正解决问题的是这个参数:ZEPPELIN_LOCAL_IP
AI给的环境变量:
2
3
4
5
6
7
8
9
10
11
12
13
SPARK_HOME=/Users/kxr/learning/spark/spark-3.5.6-bin-hadoop3;
HADOOP_CONF_DIR=$SPARK_HOME/conf;
USE_HADOOP=false;
ZEPPELIN_ADDR="127.0.0.1";
ZEPPELIN_PORT=8080;
ZEPPELIN_LOCAL_IP="127.0.0.1";
SPARK_LOCAL_IP="127.0.0.1";
SPARK_PUBLIC_DNS="127.0.0.1";
ZEPPELIN_JAVA_OPTS="-Dfile.encoding=UTF-8 -XX:+UseG1GC";
ZEPPELIN_MEM="-Xms1024m -Xmx2048m -XX:MaxMetaspaceSize=512m";
PYSPARK_PYTHON=python3;
PYSPARK_DRIVER_PYTHON=python3;
在IDEA启动配置上 新增环境变量:ZEPPELIN_LOCAL_IP=127.0.0.1,问题就修复好了。
2)扩展知识
ZEPPELIN_LOCAL_IP与ZEPPELIN_ADDR的作用与区别:
- zeppelin.server.addr (ZEPPELIN_ADDR):
控制Zeppelin Web服务器绑定的地址
决定用户通过哪个IP访问Zeppelin Web UI
主要影响的是外部访问Zeppelin服务器的地址
- zeppelin.local.ip (ZEPPELIN_LOCAL_IP):
控制Zeppelin服务器和解释器之间通信使用的本地IP地址
这个IP地址会被传递给解释器进程,用于解释器进程回连到Zeppelin服务器
主要影响的是解释器进程和Zeppelin服务器之间的内部通信
在调试解释器进程时,ZEPPELIN_LOCAL_IP很重要,因为它决定了解释器进程如何连接回Zeppelin服务器。如果设置不正确,解释器进程可能无法连接到Zeppelin服务器,导致代码执行失败。
实际上,日志中的InterpreterEventServer is starting at 0.0.1.1:52889,这个IP地址就是由zeppelin.local.ip配置的,或者在没有明确配置时由系统自动选择的本地IP地址。
3)刨根问底
下一个问题来了?为什么用了 0.0.1.1 这么个特殊ip
ip由来:
使用 ifconfig 看到了真的有个网络接口有个ip是 0.0.1.1
1 | utun7: flags=8051<UP,POINTOPOINT,RUNNING,MULTICAST> mtu 1500 |
1 | kxr@kxrdeMacBook-Pro ~ % lsof -i | grep "0.0.1.1" |
真的是冤有头债有主——VPN软件导致的。那么怎么就用了这个ip,以及为什么配置 ZEPPELIN_LOCAL_IP 就好了。
Zeppelin源码:
org.apache.zeppelin.interpreter.remote.RemoteInterpreterUtils#findAvailableHostAddress
1 | public static String findAvailableHostAddress() throws UnknownHostException, SocketException { |
3.3 debug zeppelin 解释器进程
1)背景知识
在 debug 熟悉 zeppelin源码的过程中,我发现一个问题,我debug不到 zeppelin 解释器 真正执行作业的代码。
这个就是我说要先看看 zeppelin的文档的原因。如果你看过了zeppelin解释器相关内容,就会发现其实zeppelin解释器运行在单独的JVM进程里的。而且你多执行几次页面作业,就发现类似日志:
1 | INFO [2025-09-18 17:19:28,473] ({Exec Stream Pumper} ProcessLauncher.java[processLine]:193) - [INFO] Interpreter launch command: /Users/kxr/learning/spark/spark-3.5.6-bin-hadoop3/bin/spark-submit --class org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer --driver-class-path :.//local-repo/spark/*:.//interpreter/spark/*:/Users/kxr/learning/zeppelin/zeppelin-interpreter-shaded/target/*:/Users/kxr/learning/zeppelin/zeppelin-zengine/target/test-classes/*:::/Users/kxr/learning/zeppelin/interpreter/zeppelin-interpreter-shaded-0.12.0.jar:/Users/kxr/learning/zeppelin/zeppelin-interpreter/target/classes:/Users/kxr/learning/zeppelin/zeppelin-zengine/target/test-classes:/Users/kxr/learning/zeppelin/interpreter/spark/spark-interpreter-0.12.0.jar:/Users/kxr/learning/spark/spark-3.5.6-bin-hadoop3/conf --driver-java-options -Dfile.encoding=UTF-8 -Dlog4j.configuration=file:///Users/kxr/learning/zeppelin/conf/log4j.properties -Dlog4j.configurationFile=file:///Users/kxr/learning/zeppelin/conf/log4j2.properties -Dzeppelin.log.file=/Users/kxr/learning/zeppelin/logs/zeppelin-interpreter-spark-shared_process-kxr-kxrdeMacBook-Pro.local.log -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8000 --conf spark.executor.memory=1g --conf spark.master=local[*] --conf spark.driver.memory=1g --conf spark.driver.cores=1 --conf spark.executor.cores=1 --conf spark.app.name=spark-shared_process --conf spark.executor.instances=2 --conf spark.webui.yarn.useProxy=false /Users/kxr/learning/zeppelin/interpreter/spark/spark-interpreter-0.12.0.jar 127.0.0.1 12345 spark-shared_process : |
通过这个日志其实可以学到很多东西。
/Users/kxr/learning/spark/spark-3.5.6-bin-hadoop3/bin/spark-submit:本地 Spark 的spark-submit可执行文件路径。--class org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer:指定启动的主类,这是 Zeppelin 远程解释器的服务类,用于 Zeppelin 与 Spark 之间的通信。--driver-class-path后面的一串路径:指定 Spark Driver 需要加载的 Java 类路径,包含 Zeppelin 解释器相关的 JAR 包、Spark 配置文件路径等,确保解释器能正确找到依赖的类。--driver-java-options后的参数:给 Spark Driver 的 JVM 传递的参数:-Dfile.encoding=UTF-8:设置文件编码为 UTF-8。-Dlog4j.configuration=...:指定 log4j 日志配置文件路径,控制日志输出格式和级别。-Dzeppelin.log.file=...:指定 Zeppelin 解释器的日志文件路径(记录解释器运行日志)。-agentlib:jdwp=...:启用 JVM 调试功能(suspend=y表示启动时暂停等待调试器连接,address=8000是调试端口)。
Spark 核心配置(–conf 参数)
这些是 Spark 作业的资源和运行参数:
spark.executor.memory=1g:每个 Executor 分配 1GB 内存。spark.master=local[*]:Spark 运行模式为本地模式,[*]表示使用所有可用 CPU 核心。spark.driver.memory=1g:Driver 进程分配 1GB 内存。spark.app.name=spark-shared_process:作业名称为spark-shared_process(Zeppelin 的共享 Spark 进程)。spark.executor.instances=2:启动 2 个 Executor 实例。
/Users/kxr/learning/zeppelin/interpreter/spark/spark-interpreter-0.12.0.jar:Zeppelin Spark 解释器的 JAR 包路径。127.0.0.1 12345 spark-shared_process:解释器服务绑定的本地地址(127.0.0.1)、端口(12345)及进程名称。
这条日志本质上是 Zeppelin 启动 Spark 解释器的详细命令记录,包含了 Spark 的运行模式、资源配置、类路径、日志设置等信息。通过这些参数,Zeppelin 成功启动了一个本地模式的 Spark 进程,并建立了与 Spark 的通信通道,以便用户在 Zeppelin 中编写和执行 Spark 代码。
解释器的进程是独立于 zeppelin服务的,所以debug不到。
2)怎么debug
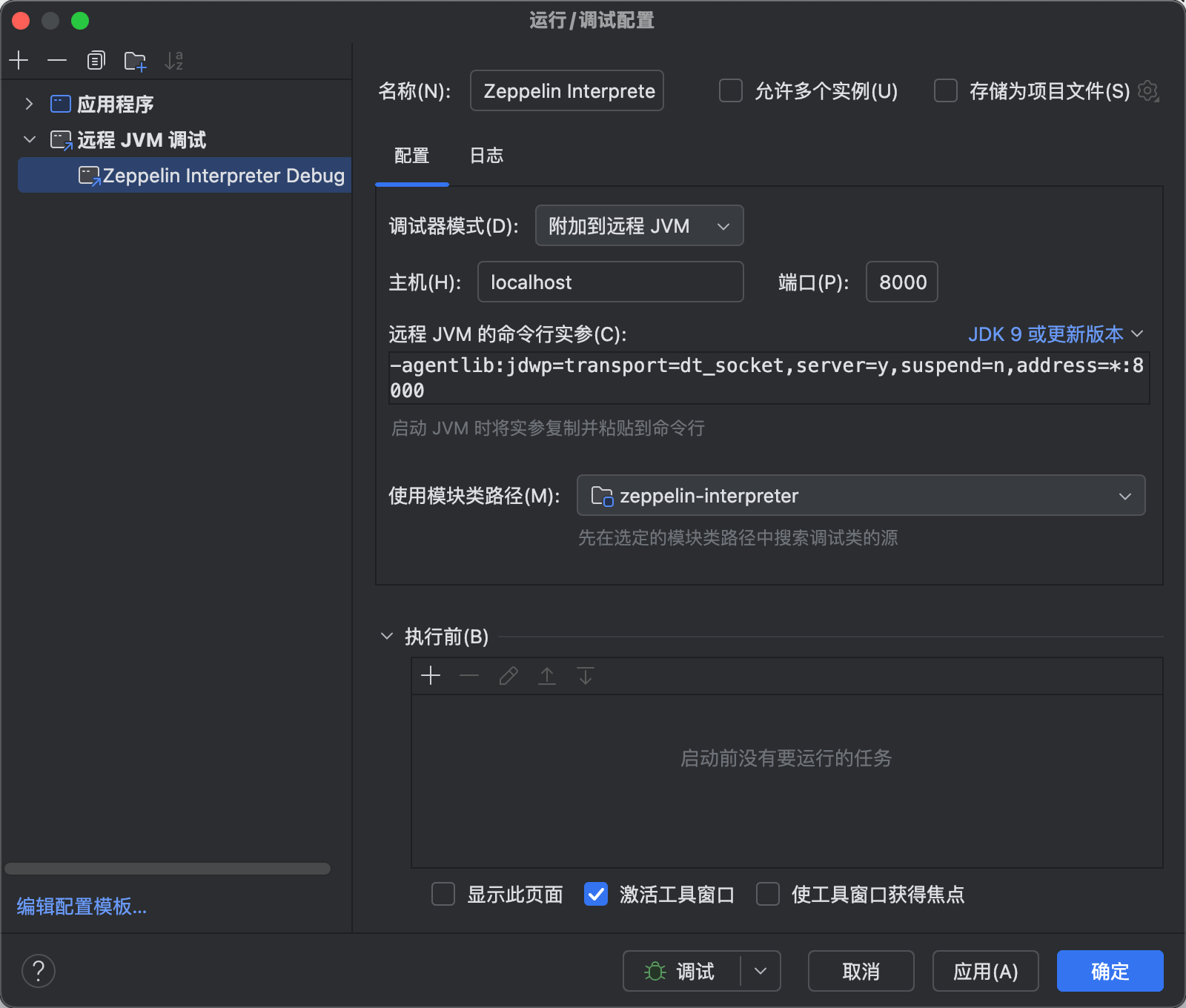
如果想要debug到,得用上 远程JVM调试。
修改
bin/interpreter.sh,这个脚本是用来控制启动 解释器的1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16if [[ -n "${SPARK_SUBMIT}" ]]; then
IFS=' ' read -r -a SPARK_SUBMIT_OPTIONS_ARRAY <<< "${SPARK_SUBMIT_OPTIONS}"
IFS='|' read -r -a ZEPPELIN_SPARK_CONF_ARRAY <<< "${ZEPPELIN_SPARK_CONF}"
if [[ "${ZEPPELIN_SPARK_YARN_CLUSTER}" == "true" ]]; then
INTERPRETER_RUN_COMMAND+=("${SPARK_SUBMIT}" "--class" "${ZEPPELIN_SERVER}" "--driver-java-options" "${SPARK_DRIVER_EXTRAJAVAOPTIONS_CONF} ${JAVA_INTP_OPTS}" "${SPARK_SUBMIT_OPTIONS_ARRAY[@]}" "${ZEPPELIN_SPARK_CONF_ARRAY[@]}" "${SPARK_APP_JAR}" "${CALLBACK_HOST}" "${PORT}" "${INTP_GROUP_ID}" "${INTP_PORT}")
else
INTERPRETER_RUN_COMMAND+=("${SPARK_SUBMIT}" "--class" "${ZEPPELIN_SERVER}" "--driver-class-path" "${ZEPPELIN_INTP_CLASSPATH_OVERRIDES}:${ZEPPELIN_INTP_CLASSPATH}" "--driver-java-options" "${SPARK_DRIVER_EXTRAJAVAOPTIONS_CONF} ${JAVA_INTP_OPTS}" "${SPARK_SUBMIT_OPTIONS_ARRAY[@]}" "${ZEPPELIN_SPARK_CONF_ARRAY[@]}" "${SPARK_APP_JAR}" "${CALLBACK_HOST}" "${PORT}" "${INTP_GROUP_ID}" "${INTP_PORT}")
fi
elif [[ -n "${ZEPPELIN_FLINK_APPLICATION_MODE}" ]]; then
IFS='|' read -r -a ZEPPELIN_FLINK_APPLICATION_MODE_CONF_ARRAY <<< "${ZEPPELIN_FLINK_APPLICATION_MODE_CONF}"
INTERPRETER_RUN_COMMAND+=("${FLINK_HOME}/bin/flink" "run-application" "-c" "${ZEPPELIN_SERVER}" "-t" "${ZEPPELIN_FLINK_APPLICATION_MODE}" "${ZEPPELIN_FLINK_APPLICATION_MODE_CONF_ARRAY[@]}" "${FLINK_APP_JAR}" "${CALLBACK_HOST}" "${PORT}" "${INTP_GROUP_ID}" "${INTP_PORT}")
else
IFS=' ' read -r -a JAVA_INTP_OPTS_ARRAY <<< "${JAVA_INTP_OPTS}"
IFS=' ' read -r -a ZEPPELIN_INTP_MEM_ARRAY <<< "${ZEPPELIN_INTP_MEM}"
INTERPRETER_RUN_COMMAND+=("${ZEPPELIN_RUNNER}" "${JAVA_INTP_OPTS_ARRAY[@]}" "${ZEPPELIN_INTP_MEM_ARRAY[@]}" "-cp" "${ZEPPELIN_INTP_CLASSPATH_OVERRIDES}:${ZEPPELIN_INTP_CLASSPATH}" "${ZEPPELIN_SERVER}" "${CALLBACK_HOST}" "${PORT}" "${INTP_GROUP_ID}" "${INTP_PORT}")
fi修改调整,增加:-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8000
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42if [[ -n "${SPARK_SUBMIT}" ]]; then
# 将空格分隔的 Spark 提交选项拆分为数组
IFS=' ' read -r -a SPARK_SUBMIT_OPTIONS_ARRAY <<< "${SPARK_SUBMIT_OPTIONS}"
# 将 | 分隔的 Zeppelin Spark 配置拆分为数组
IFS='|' read -r -a ZEPPELIN_SPARK_CONF_ARRAY <<< "${ZEPPELIN_SPARK_CONF}"
# 判断是否为 YARN 集群模式
if [[ "${ZEPPELIN_SPARK_YARN_CLUSTER}" == "true" ]]; then
# YARN 集群模式的启动命令
INTERPRETER_RUN_COMMAND+=("${SPARK_SUBMIT}" "--class" "${ZEPPELIN_SERVER}"
"--driver-java-options" "${SPARK_DRIVER_EXTRAJAVAOPTIONS_CONF} ${JAVA_INTP_OPTS}"
"${SPARK_SUBMIT_OPTIONS_ARRAY[@]}" "${ZEPPELIN_SPARK_CONF_ARRAY[@]}"
"${SPARK_APP_JAR}" "${CALLBACK_HOST}" "${PORT}" "${INTP_GROUP_ID}" "${INTP_PORT}")
else
# 非 YARN 模式(如本地模式)的启动命令,额外添加:
# - driver-class-path:指定驱动类路径
# - 调试参数:-agentlib:jdwp=...(允许远程调试)
INTERPRETER_RUN_COMMAND+=("${SPARK_SUBMIT}" "--class" "${ZEPPELIN_SERVER}"
"--driver-class-path" "${ZEPPELIN_INTP_CLASSPATH_OVERRIDES}:${ZEPPELIN_INTP_CLASSPATH}"
"--driver-java-options" "${SPARK_DRIVER_EXTRAJAVAOPTIONS_CONF} ${JAVA_INTP_OPTS} -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8000"
"${SPARK_SUBMIT_OPTIONS_ARRAY[@]}" "${ZEPPELIN_SPARK_CONF_ARRAY[@]}"
"${SPARK_APP_JAR}" "${CALLBACK_HOST}" "${PORT}" "${INTP_GROUP_ID}" "${INTP_PORT}")
fi
elif [[ -n "${ZEPPELIN_FLINK_APPLICATION_MODE}" ]]; then
# 将 | 分隔的 Flink 配置拆分为数组
IFS='|' read -r -a ZEPPELIN_FLINK_APPLICATION_MODE_CONF_ARRAY <<< "${ZEPPELIN_FLINK_APPLICATION_MODE_CONF}"
# 组装 Flink 应用模式启动命令
INTERPRETER_RUN_COMMAND+=("${FLINK_HOME}/bin/flink" "run-application"
"-c" "${ZEPPELIN_SERVER}" "-t" "${ZEPPELIN_FLINK_APPLICATION_MODE}"
"${ZEPPELIN_FLINK_APPLICATION_MODE_CONF_ARRAY[@]}"
"${FLINK_APP_JAR}" "${CALLBACK_HOST}" "${PORT}" "${INTP_GROUP_ID}" "${INTP_PORT}")
else
# 拆分 Java 选项和内存配置为数组
IFS=' ' read -r -a JAVA_INTP_OPTS_ARRAY <<< "${JAVA_INTP_OPTS}"
IFS=' ' read -r -a ZEPPELIN_INTP_MEM_ARRAY <<< "${ZEPPELIN_INTP_MEM}"
# 组装默认解释器启动命令(直接用 Java 运行)
INTERPRETER_RUN_COMMAND+=("${ZEPPELIN_RUNNER}"
"${JAVA_INTP_OPTS_ARRAY[@]}" "${ZEPPELIN_INTP_MEM_ARRAY[@]}"
"-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8000" # 调试参数
"-cp" "${ZEPPELIN_INTP_CLASSPATH_OVERRIDES}:${ZEPPELIN_INTP_CLASSPATH}" # 类路径
"${ZEPPELIN_SERVER}" "${CALLBACK_HOST}" "${PORT}" "${INTP_GROUP_ID}" "${INTP_PORT}")
fi配置idea 远程JVM调试
选择8000端口即可,因为在解释器启动脚本那配置的就是8000。然后得在页面执行作业之后,才启动解释器进程哈,所以我们也不用提前debug。我们调试参数中有
suspend=y,启动 JVM 时会暂停程序执行,直到远程调试器连接成功后才继续运行,所以不用担心。
四、打包部署
4.1 标准部署方式
为了体现打包的是我们自己编译的源码,可以留个痕迹:
我在方法org.apache.zeppelin.notebook.Paragraph#jobRun 第一行加了一个日志打印:
1 | LOGGER.info("KXR just passing through"); |
如果打包之后的 zeppelin 在运行作业时,日志出现这条日志,那么证明就成功了。
1)编译打包
使用 ./mvnw clean package -Pbuild-distr 来进行打包。
打包完成之后,在项目根目录下会生成一个打包好的分发版本,位于项目的:
zeppelin-distribution/target/zeppelin-0.12.0-bin/zeppelin-0.12.0-bin
2)部署执行
可以将这个文件夹上传到服务器,然后执行 ./bin/zeppelin-daemon.sh start
3)运行笔记,观察日志:
1 | INFO [2025-09-18 21:02:02,360] ({FIFO-RemoteInterpreter-spark-shared_process-shared_session-1} AbstractScheduler.java[runJob]:131) - Job paragraph_1758022969766_1777889232 started by scheduler RemoteInterpreter-spark-shared_process-shared_session |
成功啦
4.2 Docker部署
官方文档:https://zeppelin.apache.org/docs/0.12.0/setup/deployment/docker
Zeppelin提供了多种Docker镜像构建和部署方式,这是因为从0.9版本开始,Zeppelin支持在Kubernetes或Docker中运行,并且采用了服务器和解释器分离的架构设计。
1)服务器和解释器分离部署方式
这种方式下有三种镜像:
基础分发镜像(zeppelin-distribution)
作用 :这是一个中间镜像,主要用于构建和打包Zeppelin的所有组件
内容 :包含完整的Zeppelin源代码、构建工具和构建过程中生成的所有JAR包
特点 :体积较大,包含编译环境和构建工具
用途 :不直接用于部署,而是作为其他镜像的基础
Zeppelin服务器镜像
- 作用 :这是实际运行Zeppelin服务器的镜像
- 内容 :只包含运行Zeppelin服务器所需的组件,不包含构建工具
- 特点 :体积相对较小,优化用于生产环境
- 用途 :直接用于部署Zeppelin服务器
解释器基础镜像
构建流程关系
首先构建基础分发镜像,在这个过程中完成Zeppelin的编译和打包
然后基于这个分发镜像,提取出服务器部分创建服务器镜像
同样基于分发镜像,提取出解释器部分创建解释器镜像。
这种多阶段构建方式的好处是:
分离构建环境和运行环境,减小最终镜像大小
允许服务器和解释器分别部署,实现微服务架构
便于单独更新或扩展某个组件
实操镜像构建:
1 | #首先构建基础分发镜像 |
docker compose 部署
编写 docker-compose.yml
1 | version: '3' |
直接docker部署:
要让zeppelin-server使用单独的容器运行解释器,需要:
- 在启动容器时设置环境变量: ZEPPELIN_RUN_MODE=docker
- 指定解释器容器镜像: ZEPPELIN_DOCKER_CONTAINER_IMAGE=zeppelin-interpreter-base:latest
- 确保挂载Docker套接字: -v /var/run/docker.sock:/var/run/docker.sock
1 | docker run -p 8080:8080 \ |
2)服务器和解释器一体化部署
如果你是快速搭建开发与测试环境,可以接受zeppelin服务端与解释器运行在一个容器内。则有一种更加简单的镜像构建方式:
1 | cd $ZEPPELIN_HOME |
这种方式适合以下场景:
- 快速开始使用Zeppelin进行开发或测试
- 不需要服务器和解释器分离部署
- 想要一个更轻量级的镜像
- 需要对镜像进行简单定制