Zeppelin 使用体验
Zeppelin 使用体验
XRZeppelin部署使用
官方下载页面:https://zeppelin.apache.org/download.html
官方文档页面:https://zeppelin.apache.org/docs/0.12.0/
1.背景:
学习这个工具的原因,是因为后面想要调研——是否可以将 zeppelin 的spark解释器拆解出来集成到系统中。
2.核心功能与用途
1. 支持多语言的 “交互式笔记本(Notebook)”
这是 Zeppelin 最核心的功能,类似 Jupyter Notebook,但对大数据工具的适配更深入:
多语言内核支持
:自带对主流数据处理语言 / 框架的集成,无需额外复杂配置,例如:
- 大数据计算:Spark(Scala/Python/Java)、Flink、Hive、Pig;
- 脚本语言:Python、R、Shell、SQL;
- 其他:Markdown(写注释 / 报告)、JDBC(连接 MySQL/PostgreSQL 等关系型数据库)。
“代码块 + 即时执行” 模式:将代码拆分为多个 “段落(Paragraph)”,每个段落可独立执行(无需等待整个脚本跑完),执行结果(文本、表格、图表)实时显示在代码下方,方便快速调试和迭代(比如数据清洗时,每一步都能验证结果是否正确)。
2. 无缝集成大数据生态
Zeppelin 天生为大数据场景设计,能轻松对接 Hadoop/Spark 集群(这也适配你之前提到的 “Zeppelin 单独部署、Spark-Hadoop 集群单独部署” 的架构):
- 无需在本地安装复杂的大数据环境,只需在 Zeppelin 中配置 Spark/Hadoop 的连接信息(如 YARN 资源管理器地址、Spark Master 地址),即可直接提交任务到远程集群执行;
- 支持读取 HDFS、Hive 表、HBase 等分布式存储中的数据,无需手动写复杂的文件路径或连接逻辑。
3. 内置可视化与报告生成
数据分析的核心是 “让结果易懂”,Zeppelin 简化了可视化流程:
- 执行 SQL/Spark 代码后,结果表格可直接一键转换为柱状图、折线图、饼图、地图等可视化图表(无需额外写 Matplotlib/Seaborn 代码);
- 整个 Notebook(含代码、注释、图表)可导出为 HTML/PDF,或直接分享链接给团队,方便协作与汇报(比如数据分析报告可直接在 Zeppelin 中写完,无需再复制到 Word/PPT)。
4. 任务调度与共享协作
除了交互式分析,Zeppelin 还支持自动化与团队协作:
- 可将 Notebook 设置为定时任务(如每天凌晨执行数据清洗脚本,生成日报图表),执行结果可通过邮件推送;
- 支持多用户权限管理(如管理员、分析师、只读用户),团队成员可共同编辑一个 Notebook,或查看他人的分析成果,避免重复劳动。
5.典型使用场景
- 大数据探索与调试:数据工程师在开发 Spark 任务时,用 Zeppelin 分段执行代码,实时查看中间结果,快速定位 bug(比直接提交完整 Jar 包到 YARN 调试效率高得多);
- 数据分析与可视化:数据分析师用 SQL 查询 Hive 表,或用 Python 处理数据,直接在 Notebook 中生成可视化图表,快速输出分析结论;
- 数据科学建模:数据科学家用 Spark MLlib 或 Python 的 Scikit-learn 构建模型,分段执行特征工程、模型训练、效果评估代码,实时调整参数;
- 团队知识沉淀:将常用的数据分析流程、脚本模板、业务报告以 Notebook 形式保存在 Zeppelin 中,方便新人复用或团队共享经验。
3.实操部署
(1)下载spark、启动zeppelin
zeppelin最新版本是0.12.0,目前暂时不支持spark4。不过我看下个版本可能就会支持,已经看到了对于spark4.0官方支持的代码提交记录了。zeppelin 0.12.0 要求spark版本在spark-3.2以上,这里我选用的是spark-3.5.6。
spark下载地址:https://spark.apache.org/downloads.html
下载之后解压放在当前目录下,然后docker部署:
1 | docker run -p 8089:8080 -v ./spark-3.5.6-bin-hadoop3:/opt/spark -e SPARK_HOME=/opt/spark --rm --name zeppelin apache/zeppelin:0.12.0 |
启动起来就可以访问:http://localhost:8089/
(2)新建 new Note
1 | %spark |
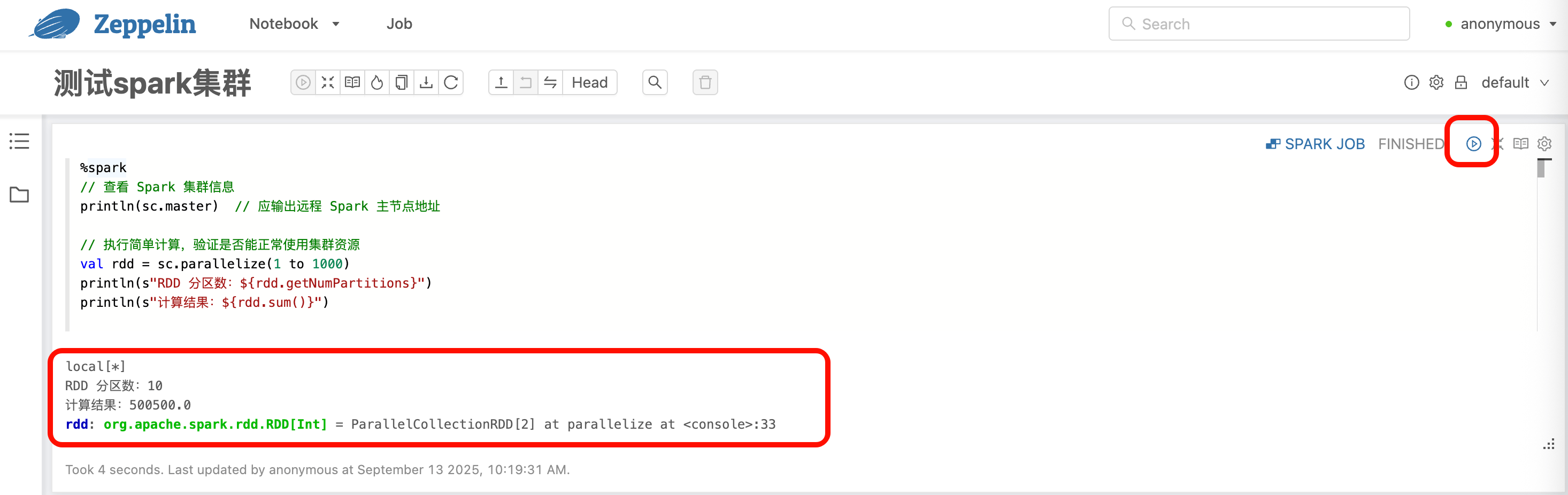
就可以点击 执行图标(Run paragraph)
看到正确的输出结果,其实你就已经完成了一个小demo了。
(3)配置spark解释器
页面右上角有可以配置zeppelin 各种解释器入口:http://localhost:8089/#/interpreter
如下是默认的 zeppelin spark解释器配置:
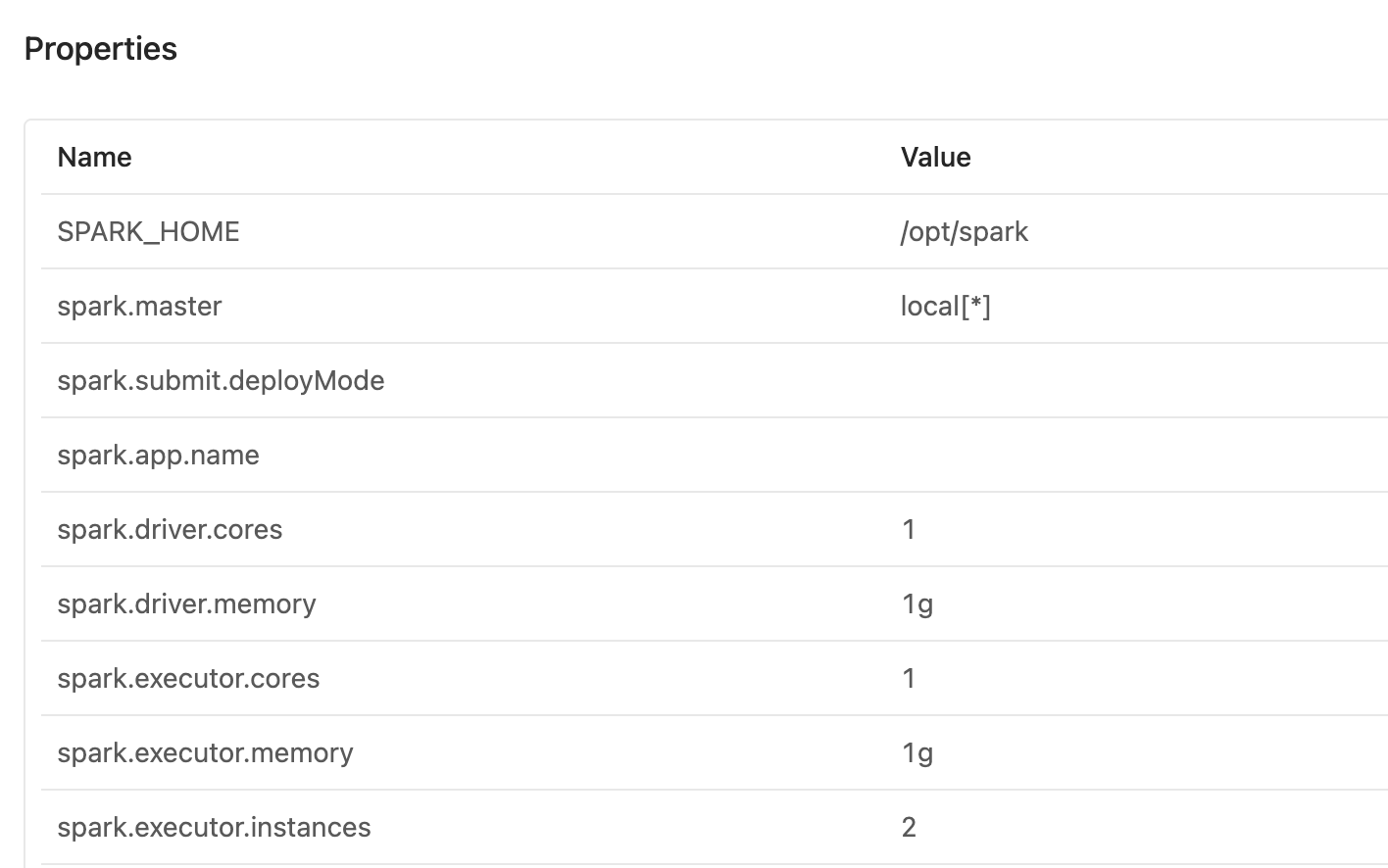
如果你希望配置spark集群:
| name | value | 备注 |
|---|---|---|
| SPARK_HOME | /opt/spark | spark安装地址 |
| spark.master | spark://master:7077 | spark主节点地址 |
如果想要提交到yarn上执行:
| name | value | 备注 |
|---|---|---|
| SPARK_HOME | /opt/spark | spark安装地址 |
| spark.master | yarn | spark主节点地址 |
| spark.submit.deployMode | client | 可选client/cluster,代表两种提交模式 |















